
Ai 珠宝设计平台技术架构全景方案
一、硬件架构设计
采用 “私有集群 + 公有云弹性扩展” 的混合架构,平衡算力稳定性、成本可控性与峰值应对能力,适配珠宝设计场景下 “日常低负载 + 研发高峰期高负载” 的算力需求。
(一)私有硬件集群(核心算力层)
(二)公有云弹性扩展层
• 选型:对接阿里云 GPU 云服务器(型号:gn7i,搭载 RTX 4090)、腾讯云智服弹性算力池。
• 触发机制:当私有集群 GPU 使用率≥80%(持续 10 分钟)或用户请求量超阈值(≥500 并发请求)时,自动调用公有云算力,分担图片生成、抠图等计算任务。
• 数据隔离:公有云节点仅处理计算任务,不存储原始设计数据(通过加密传输临时数据,任务完成后自动销毁),保障数据安全。
二、软件部署架构
采用 “容器化 + 微服务” 部署模式,基于 Kubernetes 实现资源调度与服务编排,确保软件模块独立扩展、故障隔离,同时支持私有化部署要求。
(一)基础软件层(底层支撑)
(二)核心软件模块部署(功能实现层)
(三)私有化部署保障
• 部署包交付:提供离线部署包(含基础软件、核心模块、配置脚本),支持无外网环境下安装。
• 数据本地化:所有用户数据(设计图、训练数据)存储于私有存储服务器,不与公有云交互。
• 权限管控:通过 LDAP 协议实现企业内部用户权限管理,支持按部门、角色分配功能访问权限。
三、服务架构设计
采用 “分层微服务” 架构,将平台功能拆分为独立服务,实现 “高内聚、低耦合”,同时通过服务治理保障系统稳定性与可扩展性。
(一)服务分层与模块拆分
(二)服务治理机制
• 负载均衡:API 网关层通过 Nginx 实现 HTTP 请求负载均衡,Kubernetes 内部通过 Service 实现容器间负载均衡。
• 限流熔断:基于 Sentinel 实现接口限流(单用户≤10 并发请求),当服务异常时自动熔断,避免级联故障。
• 服务监控:通过 Prometheus 采集服务指标(CPU / 内存使用率、请求成功率、响应时间),Grafana 可视化展示,设置阈值告警(如响应时间>30 秒触发告警)。
四、技术架构全景图
(一)架构全景总览
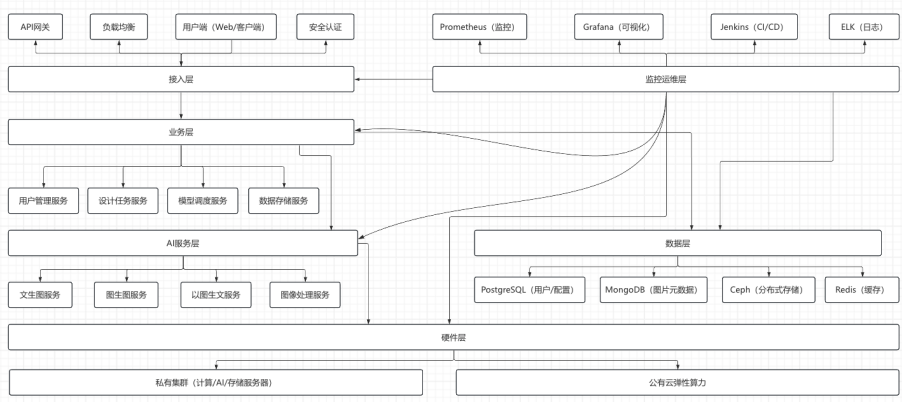
(二)核心流程示例(文生款生成)
1. 用户在前端输入提示词(如 “18K 金钻石项链,轻奢风”),选择风格引擎,提交生成请求。
2. 接入层 API 网关验证用户身份,将请求转发至业务层 “设计任务服务”。
3. “设计任务服务” 创建任务记录,调用 “模型调度服务” 分配计算资源。
4. “模型调度服务” 检查私有集群 GPU 负载,若负载≤80%,直接调用 AI 服务层 “文生图服务”;若负载>80%,触发公有云弹性算力,调用云侧 “文生图服务”。
5. “文生图服务” 加载微调后的 Stable Diffusion 模型,执行计算,生成图片结果。
6. 结果通过 “数据存储服务” 保存至 Ceph 分布式存储,同时更新任务状态。
7. 前端通过轮询或 WebSocket 获取任务结果,展示生成的款式图。
(三)架构核心优势
1. 高可用性:私有集群 + 公有云弹性扩展,避免单点故障;服务多实例部署,故障自动转移。
2. 高安全性:私有化部署保障数据本地化,多层安全防护(防火墙、认证、加密传输)防止数据泄露。
3. 高扩展性:微服务拆分支持按需扩展单个模块(如高峰期扩展 “文生图服务” 实例),硬件集群支持横向扩容(新增 AI 加速节点)。
4. 易维护性:容器化部署简化环境配置,CI/CD 实现自动化部署,监控运维层实时把控系统状态,降低运维成本。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝





